[Infra] 프론트엔드 배포 과정
면접에서 질문을 받았을 때 제대로 대답하지 못한 개념이다.
내가 평소에 관심을 가지지 않은 분야이긴하지만 알고 싶었던 분야이므로, 공부 겸 정리해보았다.
우리는 웹 페이지를 어떻게 보는가?
로컬의 HTML 파일 -> 브라우저로 열게됨 (폴더의 경로 = 웹페이지 경로)
하나의 컴퓨터, 로컬에서 웹페이지를 열 때에는 이 로컬에 있는 브라우저를 그대로 열 수 있음
즉, 파일의 위치만 알면됨
근데 우리의 컴퓨터가 아닌, 다른 사람의 브라우저, 컴퓨터로 HTML 열 때는?

remote URL(외부에 위치한 HTML을 가리키는 경로)을 알아야함.
브라우저에 입력해서 들어가볼 수 있음
로컬(내부)에서 열면 file 프로토콜, remote URL(외부)은 http 프로토콜 사용
프로토콜: 컴퓨터와 컴퓨터 사이, 또는 한 장치와 다른 장치 사이에서 데이터를 원활히 주고 받기 위하여 약속한 여러 가지 규약
배포란 무엇인가?
1. HTML 위치 탐색
2. HTML 요청
3. HTML 스펙 동작
이 3개의 동작을 보장하는 것
Static Website
정적 웹사이트: 누가 들어와도 변하지 않는 페이지
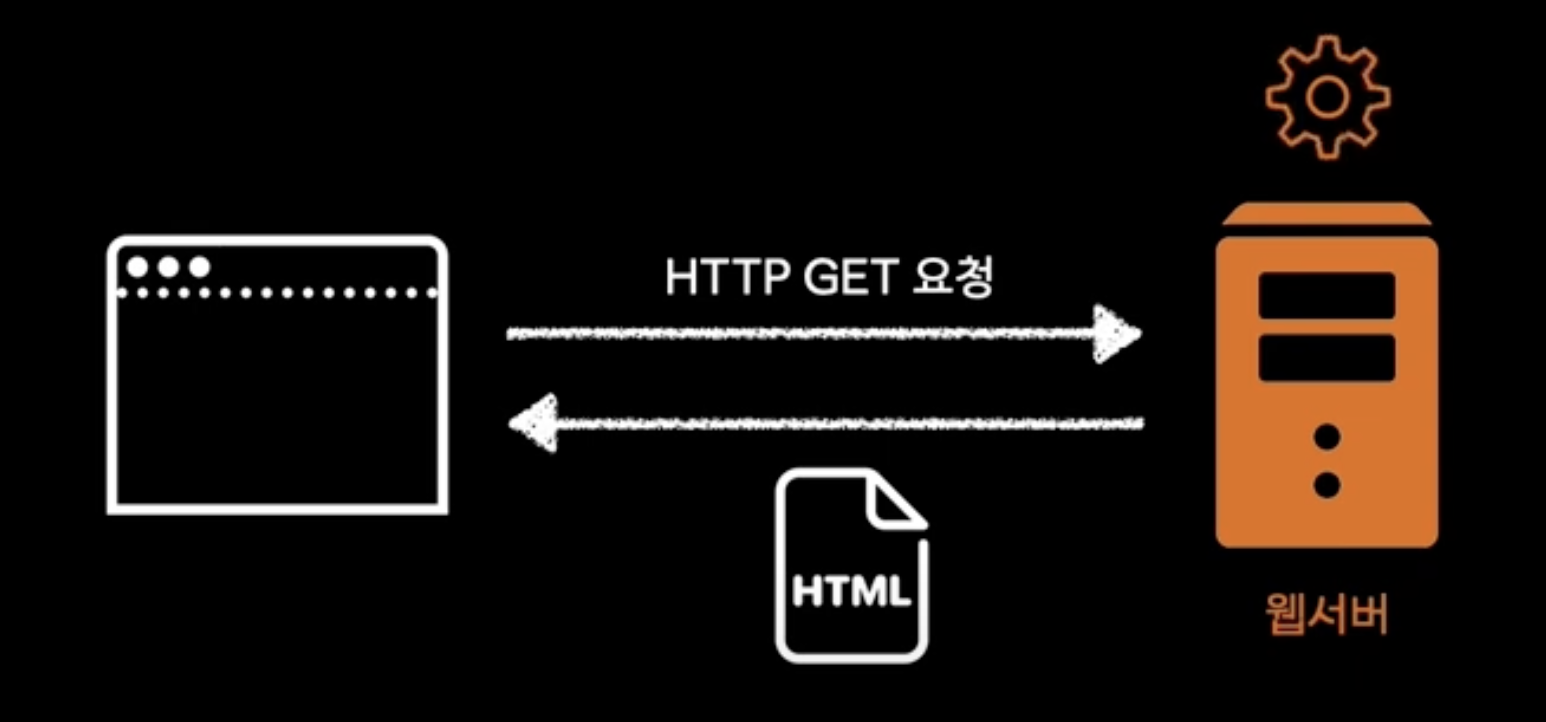
http 프로토콜을 이해해야 요청에 응답할 수 있음
웹서버의 등장
브라우저가 보낸 http 요청(GET 등)을 이해하고 처리
ex) Apache, Nginx
즉, static website의 배포 플랫폼은 단순! 웹서버만 있으면 된다.
Dynamic Website
동적 웹사이트
정적 웹사이트의 한계: 전부 동일한 HTML 전달하게됨
그러나 개인화된 웹사이트가 필요하다면, 웹사이트는 동적으로 동작할 필요가 있음.
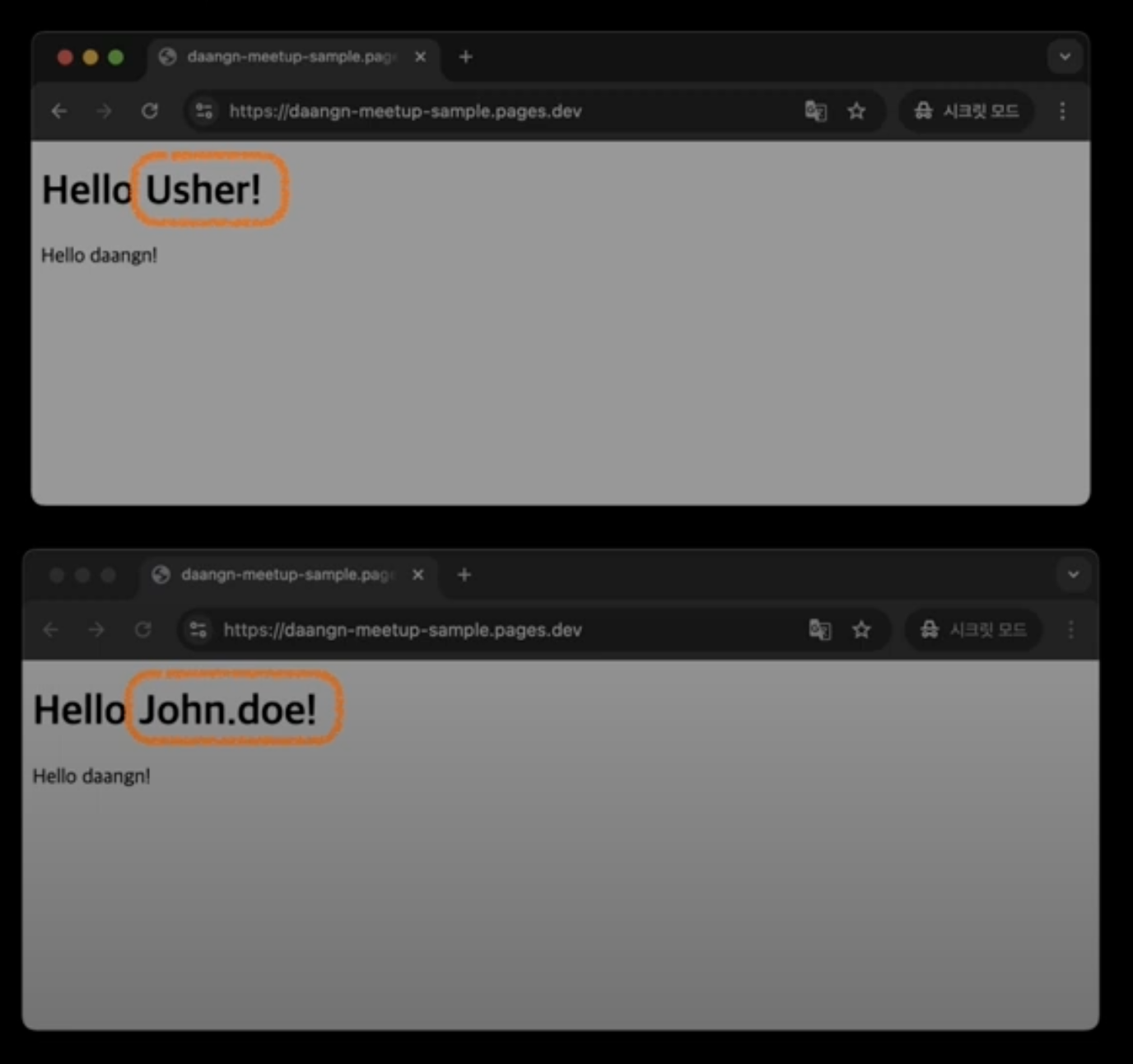
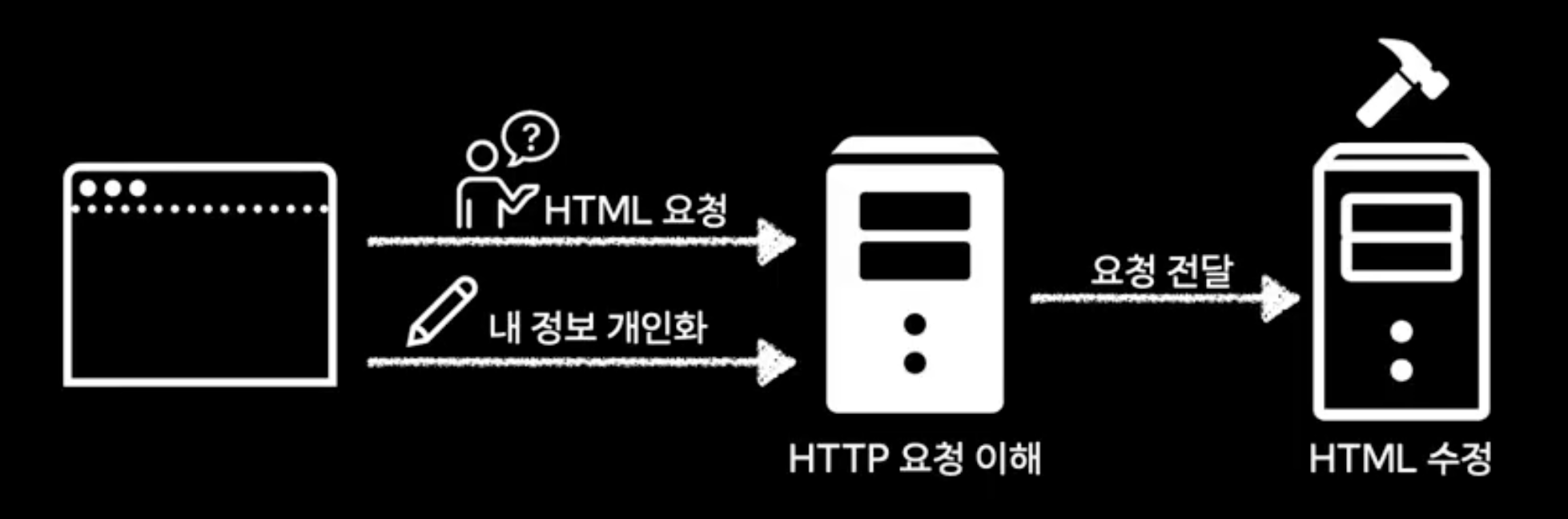
웹서버의 일이 늘어남 -> HTML을 개인화된 정보에 맞게 수정해야함
웹 애플리케이션 서버의 등장
http 요청을 받아서 동적인 작업 처리
즉, HTML을 동적으로 제어함

Single Page application
단일 페이지 애플리케이션
웹 애플리케이션 방식의 한계
1. 매번 HTML을 새로 받아야함 = 새로 고침이 지속적으로 발생
2. 화면 표시와 데이터 처리의 결합이 강함: 한쪽 수정하는데 사이드 이펙이 있을 수 있음
-> DX(Developer Experience) 측면에서 불편함 많음
Ajax의 등장
Asynchronous JavaSciprt and XML
새로 고침 없이 데이터를 받을 수 있음
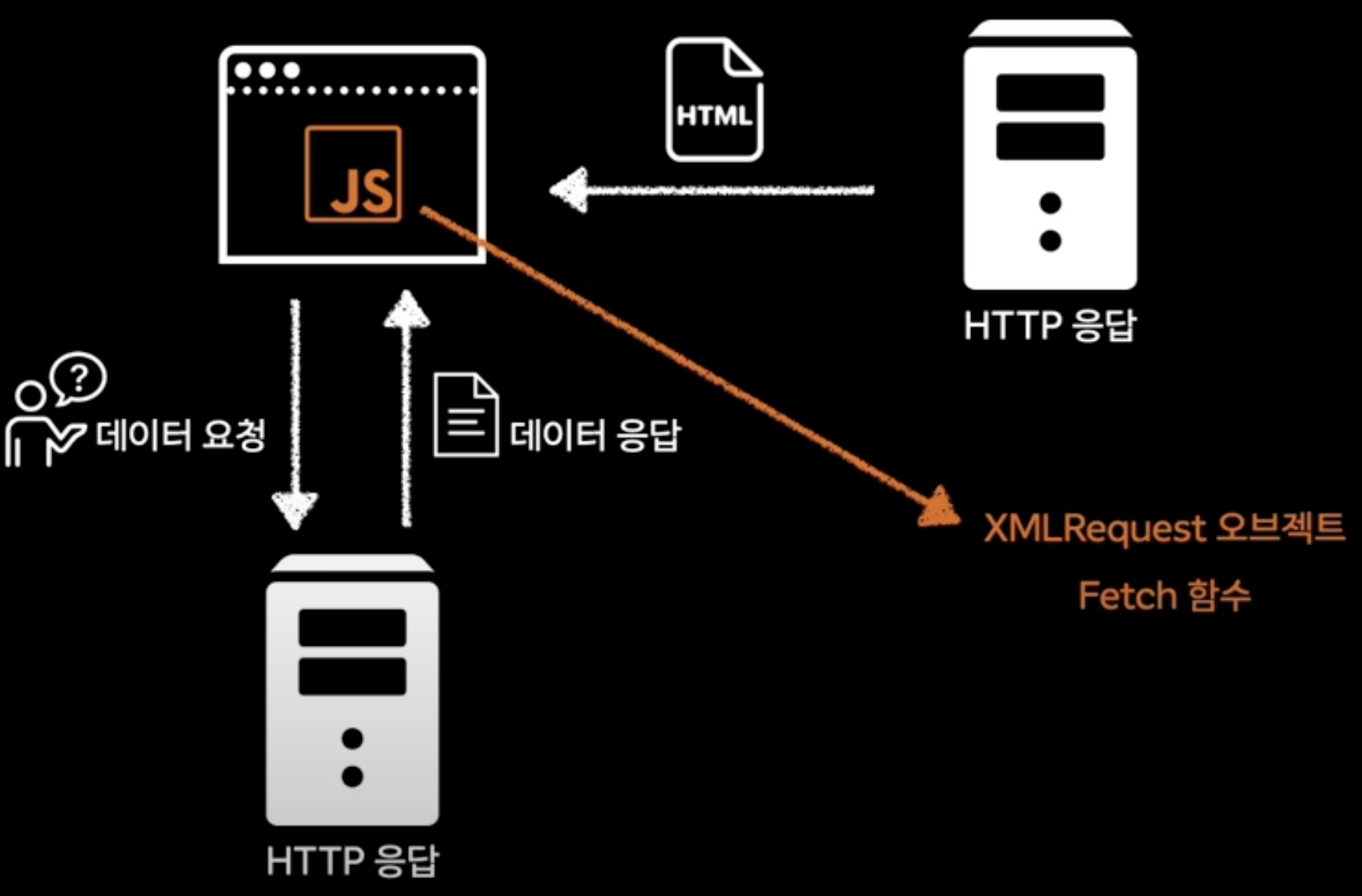
내부의 브라우저가 Ajax 스펙을 만족하는 API 통해서 가능함
1. 브라우저가 웹서버에서 HTML을 가져옴
2. 데이터를 전달해 줄 수 있는 또다른 웹서버에게 데이터를 요청하면 데이터 받아옴 -> XML Request 오브젝트 or Fetch 함수 이용
: 새로 고침 없이 데이터 가져올 수 있음!
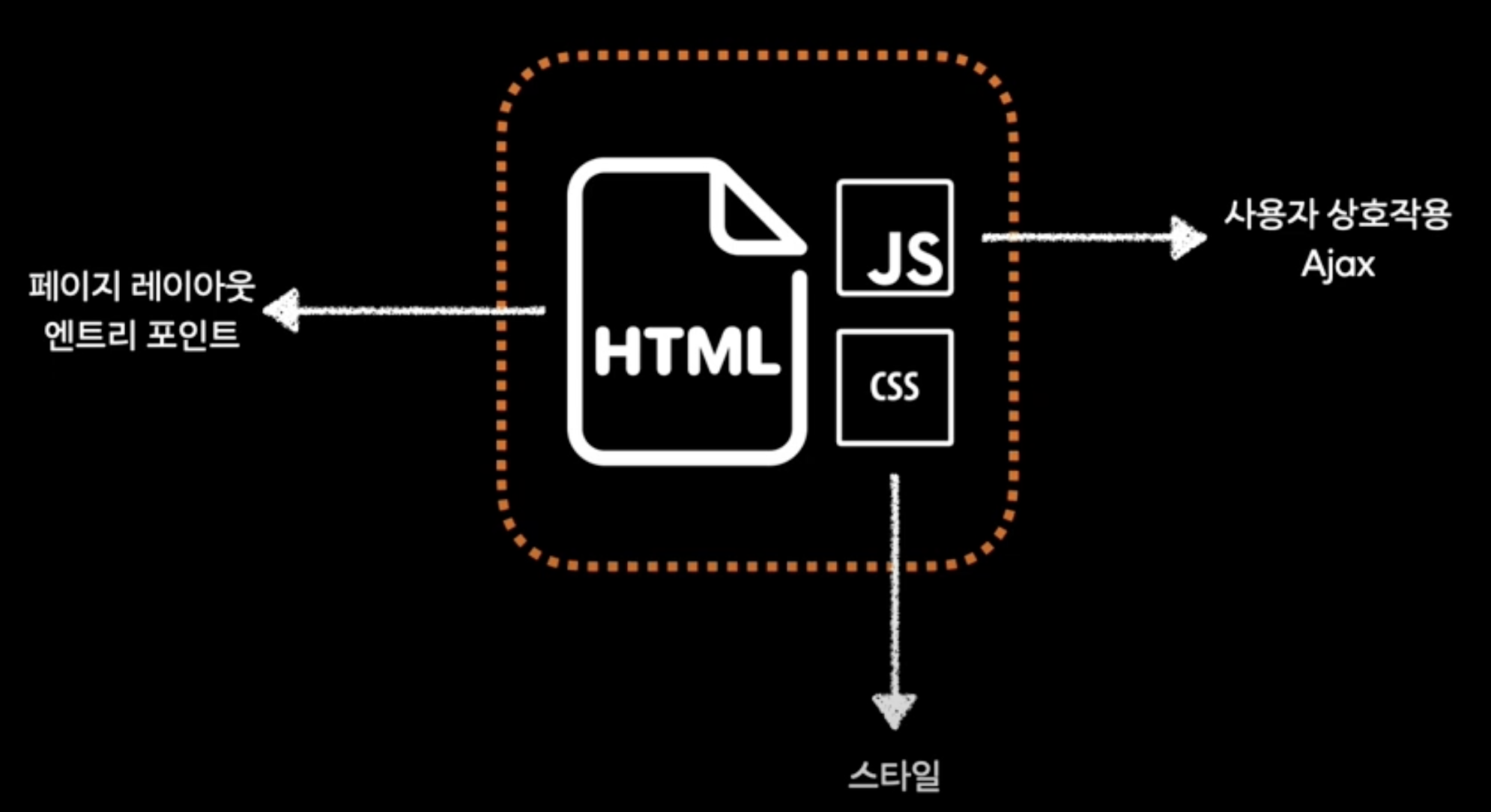

HTML, JS, CSS를 통합하는 single page applicaiton이 부상함
(직접 넣어주는건 불편하므로, 빌드 도구를 사용해 HTML에 JS와 CSS 통합)

HTML, JS가 한 요청에 한번에 내려오지 않음
웹서버에 각각 계속 요청을 해줘야함
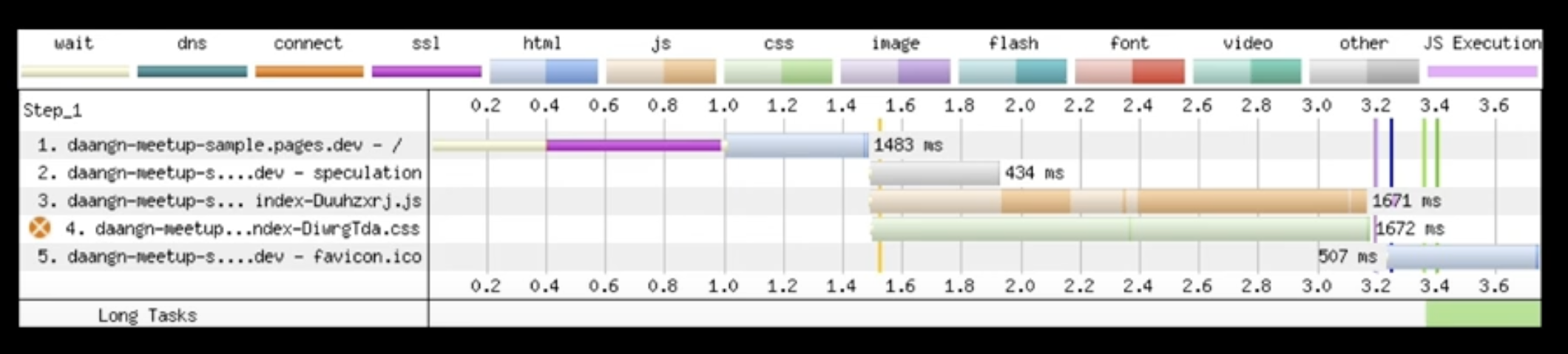
웹 서버에 반복적으로 요청하면서 waterfall 발생
SPA 웹서버란
HTTP GET 요청에 HTML, JS, CSS를 응답한다
그러나, SPA은 JS가 내부의 interaction을 담당하면서 라우팅까지 내부에서 처리하게 됨
-> sub-path를 웹서버가 다루기 어려워졌음
ex) sample.com/main으로 들어가면 HTML을 받을 수 있음
sample.com/main/profile로 들어가면 404
(예전에는 sub-path에 해당하는 동적인 페이지를 WAS, WS가 만들어줬다면, SPA 배포플랫폼에서는 이 능력 상실)
따라서 404 not found 발생 시, index.,html을 내려줌
정리: SPA 배포 플랫폼 웹서버는?
HTTP GET 요청에 HTML, JS, CSS를 응답한다
따라서 404 not found 발생 시, index.,html을 내려준다.
more SPA
SPA는 무거움, 성능 이슈: 사용자가 첫 화면을 보기 위해 요구하는 것이 많음
-> 사용자가 첫 화면을 보기 위해 기다려야함

배포 플랫폼은 어떻게 최적화 할까?
http 프로토콜 헤더로 최적화 가능!!
배포 플랫폼은 http 응답 헤더를 설정할 수 있음
성능 최적화에 기여하는 헤더: Cache-Control, Content-Length, ETag, Speculation-Rules, Link
Cache Control
기존에 받았던 HTML, JS, CSS를 추후 응답 재활용하는 캐시 정책 활용
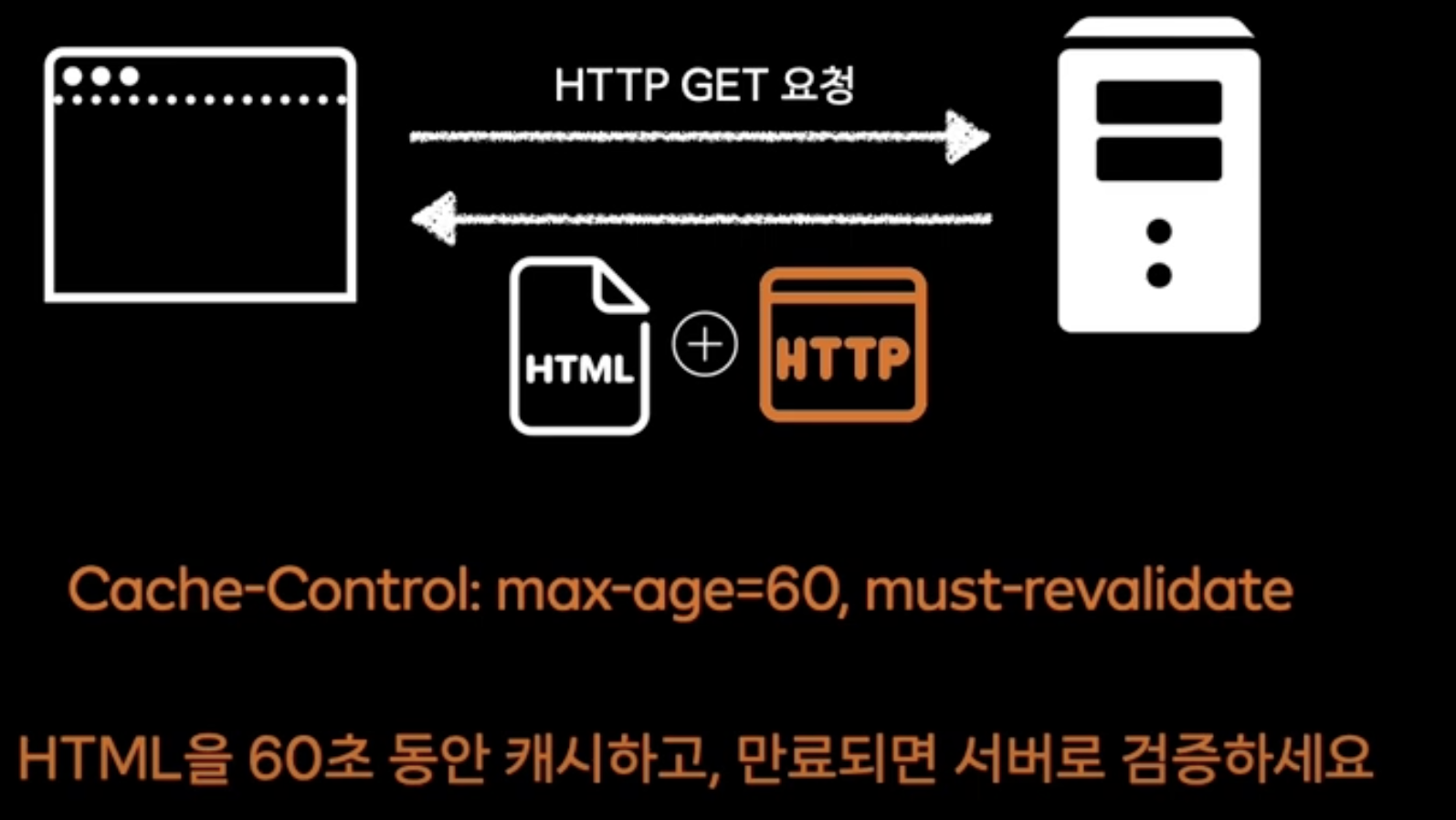

60초 동안은 웹서버를 통하지 않아도 HTML 파일 받아볼 수 있음
그럼 새로 배포를 하면?
캐시가 만료될 때까지 기다려야 하나? YES
그래서 HTML은 캐시를 생성하지 않음 -> no-store 정책
JS는 캐싱 가능 -> 만료되기를 기다려야함?
-> 빌드 도구를 통해서 HTML JS CSS 통합 가능
-> 번들링한 JS 파일에 해시가 있음

JS의 파일명은 해시로 구분
캐싱 값을 불러오는 키로 파일명을 사용하기 때문에 파일명이 다르면 캐싱으로부터 자유로움
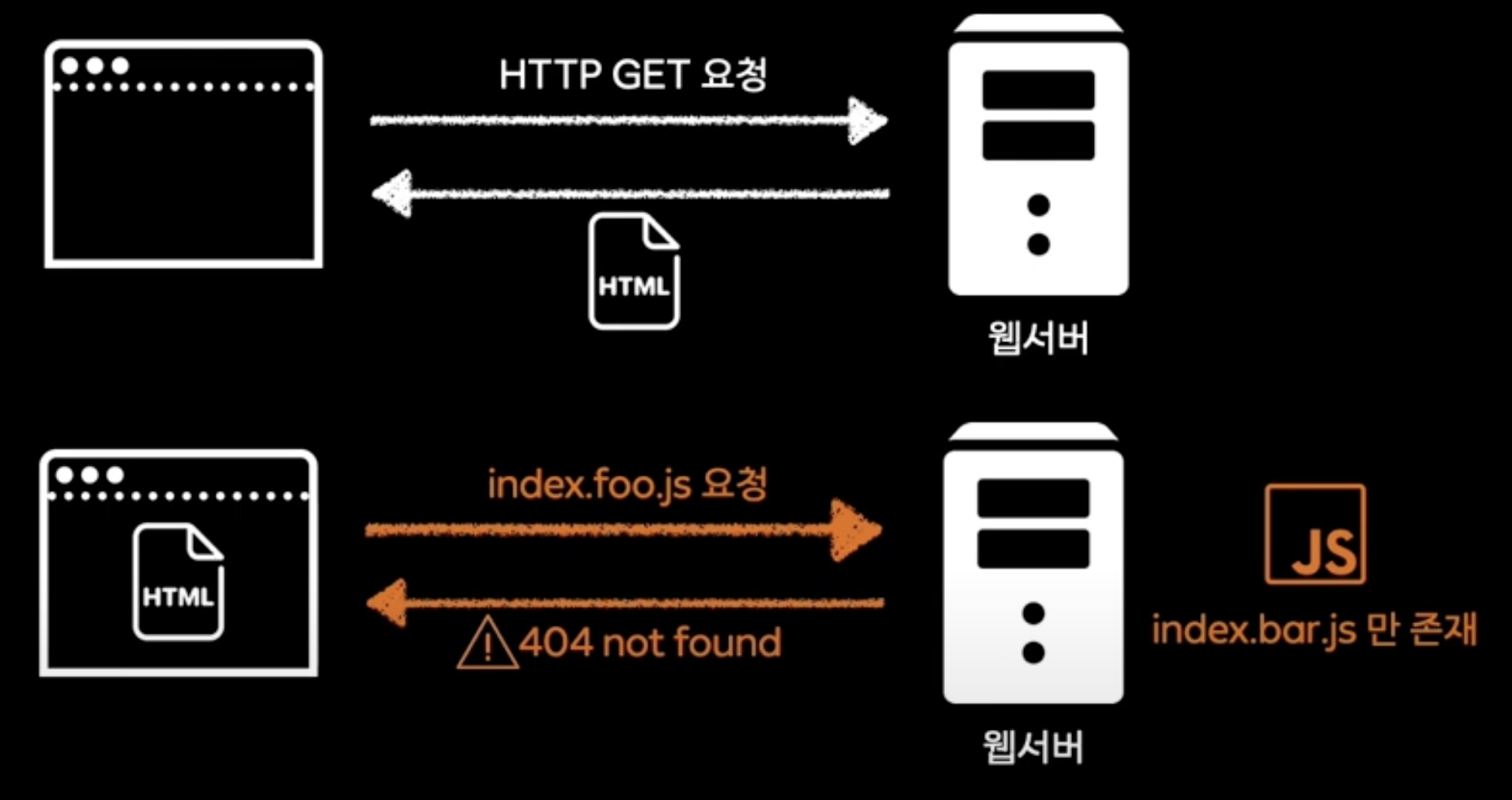
html이 요구하는 JS가 없을 수 있음
단순히 HTML 파일만 보여주면 되는게 아닌 JS 파일도 포함이 되어야 하는데,
버전이 다르면 해당 HTML이 요구하는 JS가 없을 수 있음 -> 웹 사이트가 동작하지 않음
배포 플랫폼의 버전 관리가 필요해짐! (롤백은 여전히 없음)
그래서 더 괜찮은 SPA 배포 플랫폼은?
1. HTTP GET 요청에 HTML, JS, CSS를 응답한다
2. 404 not found 발생 시, index.,html을 내려준다.
3. HTTP 헤더를 사용해서 캐시 성능을 최적화
4. Cache-Control 사용시, 캐시 정책에 따른 버전 정책을 가진다
ex) Cache-Control 사용 시, 404 not found에 따른 HTTP 응답 제공
ex) Cache-Contorl 사용 시, JS파일을 버저닝해서하고 쌓아서 보관
CDN의 등장
Content Delivery Network
HTML 성능을 높이기 위해 등장.
로컬이 아니라도 더 가깝게 HTML을 응답받을 수 있다면!

캐싱된 응답이 있다면 origin 웹서버에 요청하지 않음
HTML, JS 캐싱
CDN도 http 헤더에 영향을 받음
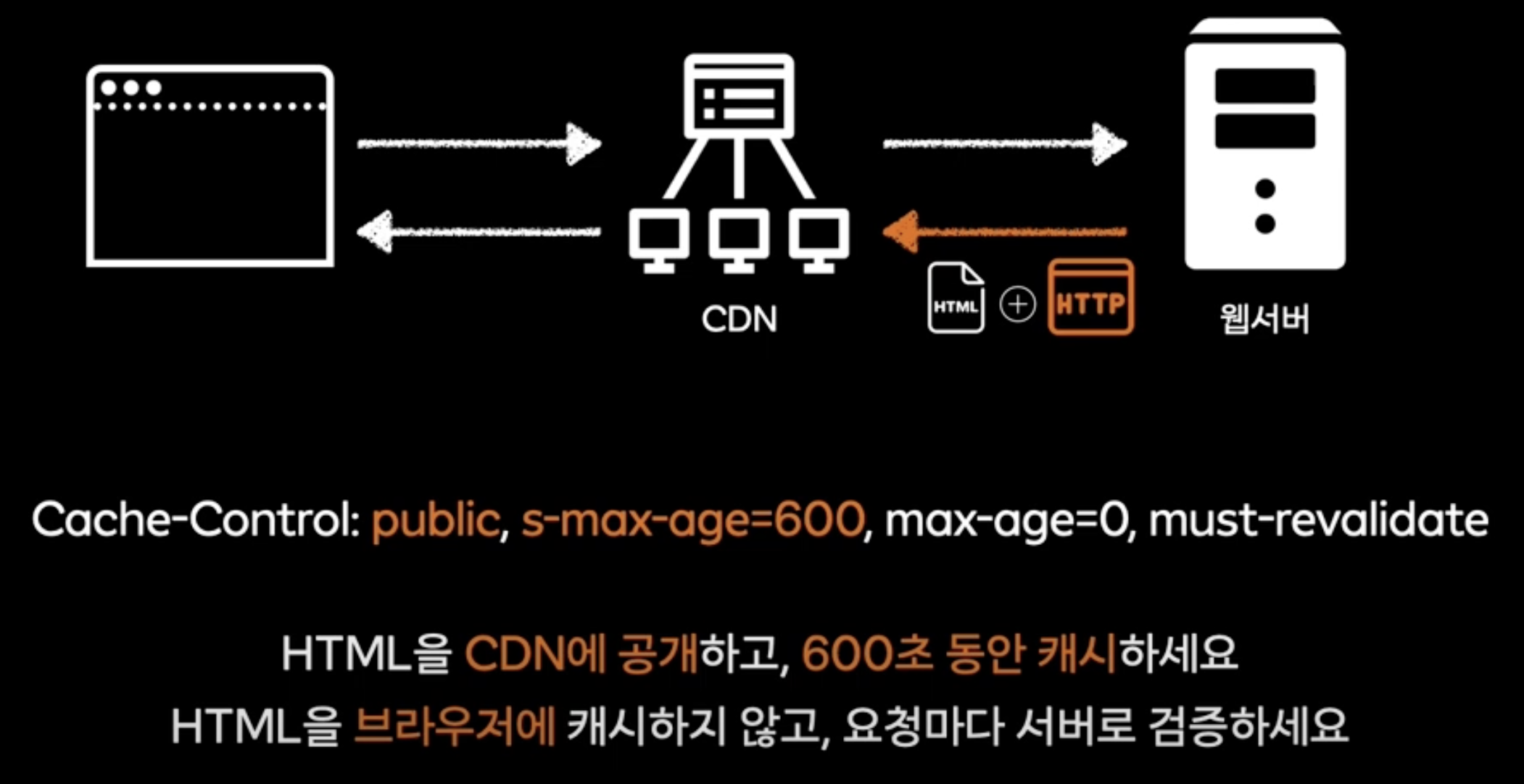
새로 배포를 한다면?
CDN의 purge
CDN의 캐싱을 무효화 시킴
사용자에게 닿기 전이니 가능
그래서 훨씬 더 괜찮은 SPA 배포 플랫폼은?
1. HTTP GET 요청에 HTML, JS, CSS를 응답한다
2. 404 not found 발생 시, index.,html을 내려준다.
3. HTTP 헤더를 사용해서 캐시 성능을 최적화
4. Cache-Control 사용시, 캐시 정책에 따른 버전 정책을 가진다
5. CDN 네트워크를 구성해서 네트워크 시간 최적화
5. CDN의 캐싱을 purge 시킴
브라우저는 어떻게 동작할까요?
navigate: html 파일을 찾고
response: html 파일을 응답받고
parse: html, js, css 파싱
render: 그리는 작업
참고자료
- 2024 당근 테크 밋업 - 프론트엔드에게 배포플랫폼이란